kubernetes+elk的日志收集
2022-12-29
21 min read
一、搭建elk集群
| 节点 | 服务端口 | 选举端口 | 目录 |
|---|---|---|---|
| 192.168.234.201 | 9200 | 9300 | /usr/local/src/node1 |
| 192.168.234.201 | 9201 | 9301 | /usr/local/src/node2 |
| 192.168.234.201 | 9202 | 9302 | /usr/local/src/node3 |
1、准备elasticsearch集群
elasticsearch搭建
#下载elasticsearch包解压
cd /usr/local/src/
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
修改elasticsearch配置
vim elasticsearch-7.17.3/config/jvm.options
-Xms3g
-Xmx3g
#配置elasticsearch.yml 此为node1可用
vim elasticsearch-7.17.3/config/elasticsearch.yml
# 集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
# 节点名称
node.name: node-1
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/src/node-1/data
# log目录
path.logs: /usr/local/src/node-1/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200
http.port: 9200
# 内部节点之间沟通端⼝
transport.tcp.port: 9300
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
上述配置文件准备好以后,将elasticsearch目录按照node1、node2、node3复制过去
#创建目录
mkdir node-{1..3}
cp -r /usr/local/elasticsearch-7.17.3/ /usr/local/node-1
cp -r /usr/local/elasticsearch-7.17.3/ /usr/local/node-2
cp -r /usr/local/elasticsearch-7.17.3/ /usr/local/node-3
#创建elasticsearch的数据目录和日志目录
mkdir -p /usr/local/node-1/data
mkdir -p /usr/local/node-1/logs
mkdir -p /usr/local/node-2/data
mkdir -p /usr/local/node-2/logs
mkdir -p /usr/local/node-3/data
mkdir -p /usr/local/node-3/logs
修改es(node-2)的配置文件
vim node-2/config/elasticsearch.yml
cluster.name: my-application
# 节点名称
node.name: node-2
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/node-2/data
# log目录
path.logs: /usr/local/node-2/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200 node-2为9201
http.port: 9201
# 内部节点之间沟通端⼝
transport.tcp.port: 9301
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
修改es(node-3)的配置文件
vim node-3/config/elasticsearch.yml
# 集群名称,三台集群,要配置相同的集群名称!!!
cluster.name: my-application
# 节点名称
node.name: node-3
# 是否有资格被选举为master,ES默认集群中第一台机器为主节点
node.master: true
# 是否存储数据
node.data: true
#最⼤集群节点数,为了避免脑裂,集群节点数最少为 半数+1
node.max_local_storage_nodes: 3
# 数据目录
path.data: /usr/local/node-3/data
# log目录
path.logs: /usr/local/node-3/logs
# 修改 network.host 为 0.0.0.0,表示对外开放,如对特定ip开放则改为指定ip
network.host: 0.0.0.0
# 设置对外服务http端口,默认为9200
http.port: 9203
# 内部节点之间沟通端⼝
transport.tcp.port: 9303
# 写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300", "localhost:9301", "localhost:9302"]
# 初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
# 设置集群中N个节点启动时进行数据恢复,默认为1
gateway.recover_after_nodes: 3
# 下面的两个配置在安装elasticsearch-head的时候会用到
# 开启跨域访问支持,默认为false
http.cors.enabled: true
# 跨域访问允许的域名地址,(允许所有域名)以上使用正则
http.cors.allow-origin: "*"
#关闭xpack
xpack.security.enabled: false
启动elasticsearch集群
groupadd elasticsearch
useradd elasticsearch -G elasticsearch -p 123456
chown -R elasticsearch:elasticsearch /usr/local/src/elasticsearch-7.17.3
chown -R elasticsearch:elasticsearch /usr/local/src/node-3
chown -R elasticsearch:elasticsearch /usr/local/src/node-2
chown -R elasticsearch:elasticsearch /usr/local/src/node-1
#将全部elasticsearch的目录所有者所属组改为elasticsearch
su elasticsearch
cd /usr/local/src/
./node-1/bin/elasticsearch -d
./node-2/bin/elasticsearch -d
./node-3/bin/elasticsearch -d
启动elasticsearch集群
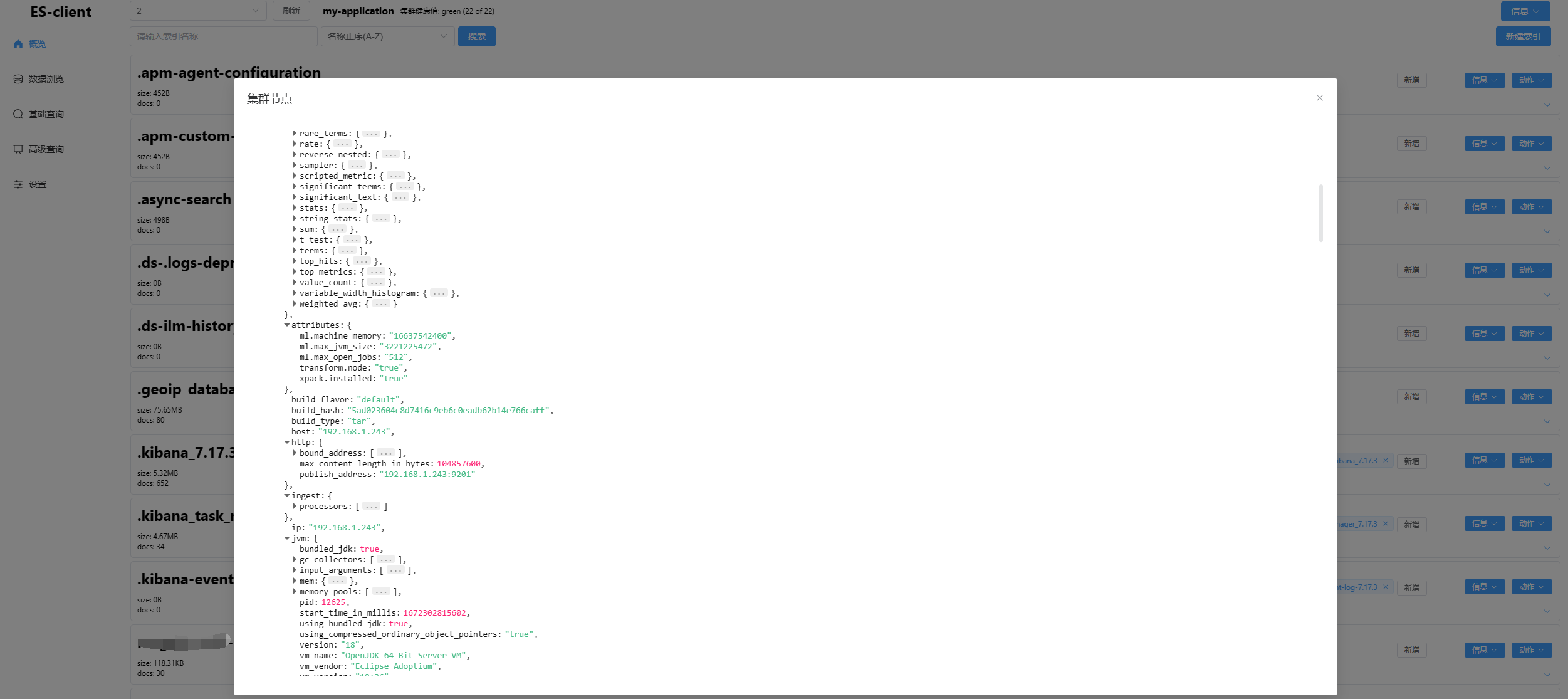

2、准备kafka
环境准备
| 节点 | 服务端口 | 程序目录 | 数据目录 | 日志目录 |
|---|---|---|---|---|
| 192.168.234.204 | 2181 | /apps/zookeeper | /data/zookeeper/data | /data/zookeeper/logs |
| 192.168.234.205 | 2181 | /apps/zookeeper | /data/zookeeper/data | /data/zookeeper/logs |
| 192.168.234.206 | 2181 | /apps/zookeeper | /data/zookeeper/data | /data/zookeeper/logs |
#下载安装zookeeper
cd /apps
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
tar xf apache-zookeeper-3.5.7-bin.tar.gz
ln -sv apache-zookeeper-3.5.7-bin zookeeper
echo "export ZK_HOME=/apps/zookeeper" >> /etc/profile
echo "export PATH=\$PATH:\$ZK_HOME/bin" >> /etc/profile
source /etc/profile
vim /apps/zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
server.1=192.168.234.204:2888:3888
server.2=192.168.234.205:2888:3888
server.3=192.168.234.206:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
集群配置
#192.168.234.204机器配置myid
echo 1 > /data/zookeeper/data/myid
#192.168.234.205机器配置myid
echo 2 > /data/zookeeper/data/myid
#192.168.234.206机器配置myid
echo 3 > /data/zookeeper/data/myid
启动zookeeper
#192.168.234.204 #192.168.234.205 #192.168.234.206
#全部执行启动命令
./zkServer.sh start
验证集群
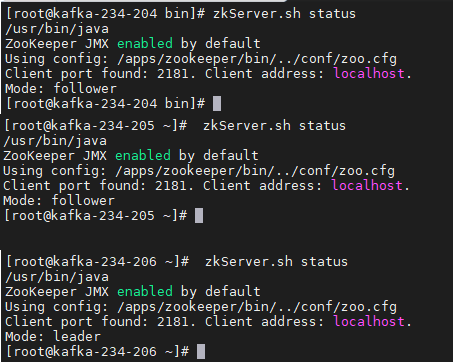
3、准备kafka
#下载kafka
mkdir /data/kafka/kafka-logs
cd /apps
wget https://archive.apache.org/dist/kafka/2.6.0/kafka_2.13-2.6.0.tgz
tar xvf kafka_2.13-2.6.0.tgz
ln -sv kafka_2.13-2.6.0 kafka
cd kafka
echo "export KAFKA_HOME=/apps/kafka" >> /etc/profile
echo "export PATH=\$PATH:\$KAFKA_HOME/bin" >> /etc/profile
source /etc/profile
#配置kafka
cp config/server.properties config/server.properties.bak
rm -rf config/server.properties
cat <<'EOF' >> /config/server.properties
#192.168.234.204 配置1
#192.168.234.205 配置2
#192.168.234.206 配置3
broker.id=1
#监听本地902端口
#其他zookeeper需要修改ip
#192.168.234.205
#192.168.234.206
listeners=PLAINTEXT://192.168.234.204:9092
#listeners=PLAINTEXT://192.168.234.205:9092
#listeners=PLAINTEXT://192.168.234.206:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/kafka/logs
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#zookeeper集群
zookeeper.connect=192.168.234.204:2181,192.168.234.205:2181,192.168.234.206:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
EOF
#启动kafka集群其他192.168.234.205 192.168.234.206均执行
apps/kafka/bin/kafka-server-start.sh -daemon apps/kafka/config/server.properties
使用kafka tool2 验证kafka
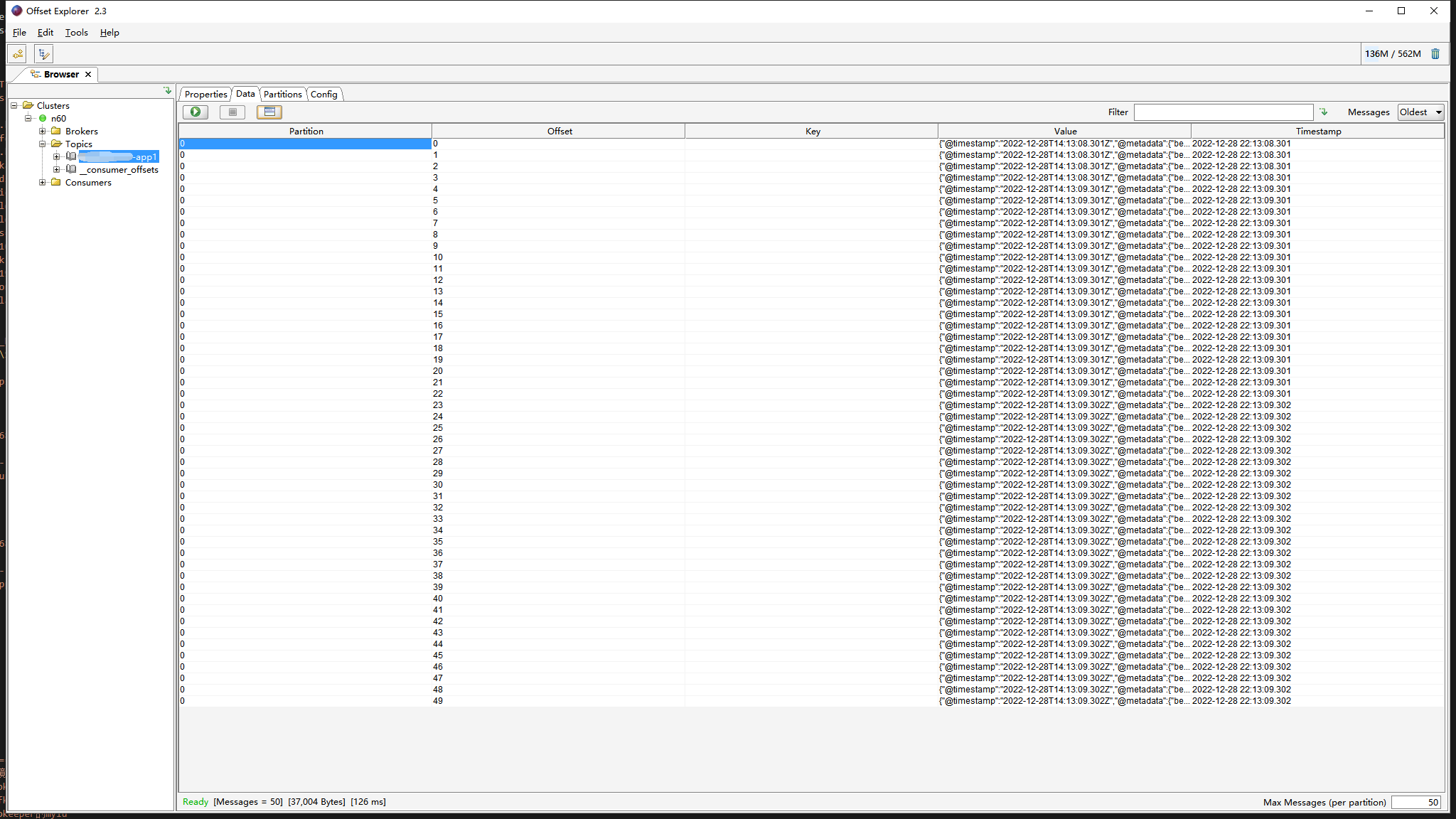
4、准备kibana
#下载解压kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.3-linux-x86_64.tar.gz
tar kibana-7.17.3-linux-x86_64.tar.gz xf
tar xf kibana-7.17.3-linux-x86_64.tar.gz
配置kibana
vim kibana-7.17.3-linux-x86_64/config/kibana.yml
server.port: 5601
#配置为es集群地址
elasticsearch.hosts: ["http://192.168.234.201:9200","http://192.168.234.201:9201","http://192.168.234.201:9202"]
i18n.locale: "zh-CN"
启动kibana
./kibana --allow-root &
验证5601端口服务启动
5、准备logstash
机器ip 192.168.234.200
#下载安装logstash
yum install -y https://artifacts.elastic.co/downloads/logstash/logstash-7.17.3-x86_64.rpm
#配置kafka
vim /etc/logstash/conf.d/kafka-es.conf
input {
kafka {
bootstrap_servers => "192.168.234.204:9092,192.168.234.205:9092,192.168.234.206:9092"
topics => ["test-n60-app1"]
codec => "json"
}
}
output {
if [fields][type] == "tomcat-accesslog" {
elasticsearch {
hosts => ["192.168.234.201:9200","192.168.234.201:9201","192.168.234.201:9203"]
index => "test-app1-accesslog-%{+YYYY.MM.dd}"
}
}
if [fields][type] == "tomcat-catalina" {
elasticsearch {
hosts => ["192.168.234.201:9200","192.168.234.201:9201","192.168.234.201:9203"]
index => "test-app1-catalinalog-%{+YYYY.MM.dd}"
}
}
}
二、准备kubernetes 测试环境
准备一个tomcat pod来测试日志收集
centos容器镜像准备好
[root@master1-etcd-234-31 centos]# ll
total 31848
-rw-r--r-- 1 root root 424 Dec 24 20:45 build-command.sh
-rw-r--r-- 1 root root 404 Dec 24 20:44 Dockerfile
-rw-r--r-- 1 root root 32600353 Dec 24 20:24 filebeat-7.12.1-x86_64.rpm
[root@master1-etcd-234-31 centos]# vim Dockerfile

FROM centos:7.9.2009
ADD filebeat-7.12.1-x86_64.rpm /tmp
RUN yum install -y /tmp/filebeat-7.12.1-x86_64.rpm vim wget tree lrzsz gcc gcc-c++ automake pcre pcre-devel zlib zlib-devel openssl openssl-devel iproute net-tools iotop && rm -rf /etc/localtime /tmp/filebeat-7.12.1-x86_64.rpm && ln -snf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && useradd nginx -u 2022
准备一个jdk镜像将java环境profile配置到centos重新构建镜像
[root@master1-etcd-234-31 jdk-1.8.212]# ll
total 190456
-rw-r--r-- 1 root root 454 Dec 24 21:25 build-command.sh
-rw-r--r-- 1 root root 392 Dec 24 21:14 Dockerfile
-rw-r--r-- 1 root root 195013152 Dec 24 20:24 jdk-8u212-linux-x64.tar.gz
-rw-r--r-- 1 root root 2105 Dec 24 20:24 profile
[root@master1-etcd-234-31 jdk-1.8.212]# cat Dockerfile profile
#JDK Base Image
FROM 192.168.234.121/baseimages/centos@sha256:5ebca0651a91576b518cf369776062d2e2b1a41d43839b7f30bafdebb027ac64
ADD jdk-8u212-linux-x64.tar.gz /usr/local/src/
RUN ln -sv /usr/local/src/jdk1.8.0_212 /usr/local/jdk
ADD profile /etc/profile
ENV JAVA_HOME /usr/local/jdk
ENV JRE_HOME $JAVA_HOME/jre
ENV CLASSPATH $JAVA_HOME/lib/:$JRE_HOME/lib/
ENV PATH $PATH:$JAVA_HOME/bin
# /etc/profile
# System wide environment and startup programs, for login setup
# Functions and aliases go in /etc/bashrc
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
pathmunge () {
case ":${PATH}:" in
*:"$1":*)
;;
*)
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
esac
}
if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`/usr/bin/id -u`
UID=`/usr/bin/id -ru`
fi
USER="`/usr/bin/id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi
# Path manipulation
if [ "$EUID" = "0" ]; then
pathmunge /usr/sbin
pathmunge /usr/local/sbin
else
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
fi
HOSTNAME=`/usr/bin/hostname 2>/dev/null`
HISTSIZE=1000
if [ "$HISTCONTROL" = "ignorespace" ] ; then
export HISTCONTROL=ignoreboth
else
export HISTCONTROL=ignoredups
fi
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
# By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is 200
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
if [ $UID -gt 199 ] && [ "`/usr/bin/id -gn`" = "`/usr/bin/id -un`" ]; then
umask 002
else
umask 022
fi
for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
unset i
unset -f pathmunge
export LANG=en_US.UTF-8
export HISTTIMEFORMAT="%F %T `whoami` "
export JAVA_HOME=/usr/local/jdk
export TOMCAT_HOME=/apps/tomcat
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$TOMCAT_HOME/bin:$PATH
export CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
准备Tomcat镜像
#Tomcat 8.5.43基础镜像
FROM 192.168.234.121/pub-images/jdk@sha256:9f17292bc4b2572f6b6936ae56a43d0d952ed53092252fcf9b1cc024fc9dd2ae
RUN mkdir /apps /data/tomcat/webapps /data/tomcat/logs -pv
ADD apache-tomcat-8.5.43.tar.gz /apps
RUN useradd tomcat -u 2050 && ln -sv /apps/apache-tomcat-8.5.43 /apps/tomcat && chown -R tomcat.tomcat /apps /data -R
准备tomcat业务镜像
[root@master1-etcd-234-31 tomcat-app1]# ll
total 56
-rw-r--r-- 1 root root 146 Dec 24 20:24 app1.tar.gz
-rw-r--r-- 1 root root 455 Dec 28 16:22 build-command.sh
-rw-r--r-- 1 root root 23611 Dec 24 20:24 catalina.sh
-rw-r--r-- 1 root root 629 Dec 30 00:06 Dockerfile
-rw-r--r-- 1 root root 670 Dec 28 22:07 filebeat.yml
-rw-r--r-- 1 root root 63 Dec 24 20:24 index.html
drwxr-xr-x 2 root root 24 Dec 24 20:24 myapp
-rw-r--r-- 1 root root 371 Dec 28 21:54 run_tomcat.sh
-rw-r--r-- 1 root root 6462 Dec 24 20:24 server.xml
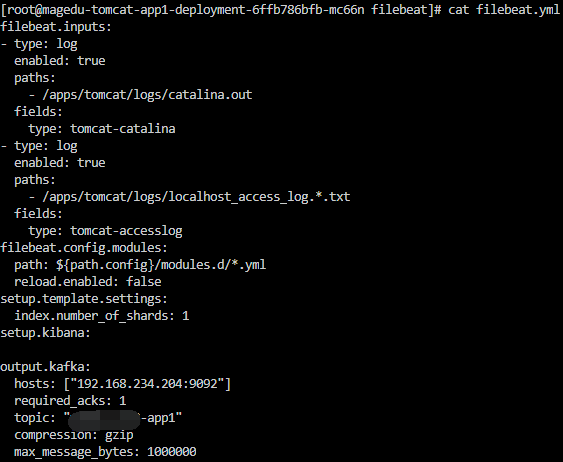
#配置vim filebeat.yml
vim filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
#定义的tomcat的日志目录
- /apps/tomcat/logs/catalina.out
fields:
type: tomcat-catalina
- type: log
enabled: true
paths:
- /apps/tomcat/logs/localhost_access_log.*.txt
fields:
type: tomcat-accesslog
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
output.kafka:
hosts: ["192.168.234.204:9092"]
required_acks: 1
#topic kafka用的
topic: "test-app1"
compression: gzip
max_message_bytes: 1000000
tomcat业务镜像需要的代码和tomcat配置
#tomcat web1
FROM 192.168.234.121/pub-images/tomcat-base@sha256:5231b823f63ebc41d8421cc082e11ad9d0900f0ec1aefce60438938799319e72
ADD catalina.sh /apps/tomcat/bin/catalina.sh
ADD server.xml /apps/tomcat/conf/server.xml
ADD myapp/* /data/tomcat/webapps/myapp/
ADD app1.tar.gz /data/tomcat/webapps/myapp/
ADD run_tomcat.sh /apps/tomcat/bin/run_tomcat.sh
ADD filebeat.yml /etc/filebeat/filebeat.yml
RUN chown -R nginx.nginx /data/ /apps/
#RUN cd /tmp && yum localinstall -y filebeat-7.5.1-amd64.deb
RUN chmod +x /apps/tomcat/bin/run_tomcat.sh /apps/tomcat/bin/catalina.sh
EXPOSE 8080 8443
CMD ["/apps/tomcat/bin/run_tomcat.sh"]
启动tomcat以及filebeat需要的脚本内容
#!/bin/bash
#echo "nameserver 223.6.6.6" > /etc/resolv.conf
#echo "192.168.7.248 k8s-vip.example.com" >> /etc/hosts
/usr/share/filebeat/bin/filebeat -e -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat -path.logs /var/log/filebeat &
su - nginx -c "/apps/tomcat/bin/catalina.sh start"
tail -f /etc/hosts
准备kubernetes要启动的tomcat pod yaml 文件
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: test-tomcat-app1-deployment-label
name: test-tomcat-app1-deployment
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: test-tomcat-app1-selector
template:
metadata:
labels:
app: test-tomcat-app1-selector
spec:
containers:
- name: test-tomcat-app1-container
image: 192.168.234.121/test/tomcatv8.5.43:20221228_221249
#command: ["/apps/tomcat/bin/run_tomcat.sh"]
#imagePullPolicy: IfNotPresent
imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits:
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
volumeMounts:
- name: test-images
mountPath: /usr/local/nginx/html/webapp/images
readOnly: false
- name: test-static
mountPath: /usr/local/nginx/html/webapp/static
readOnly: false
volumes:
- name: test-images
nfs:
server: 192.168.234.131
path: /data/k8sdata/test/images
- name: test-static
nfs:
server: 192.168.234.131
path: /data/k8sdata/test/static
# nodeSelector:
# project: test
# app: tomcat
---
kind: Service
apiVersion: v1
metadata:
labels:
app: test-tomcat-app1-service-label
name: test-tomcat-app1-service
namespace: test
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 30092
selector:
app: test-tomcat-app1-selector
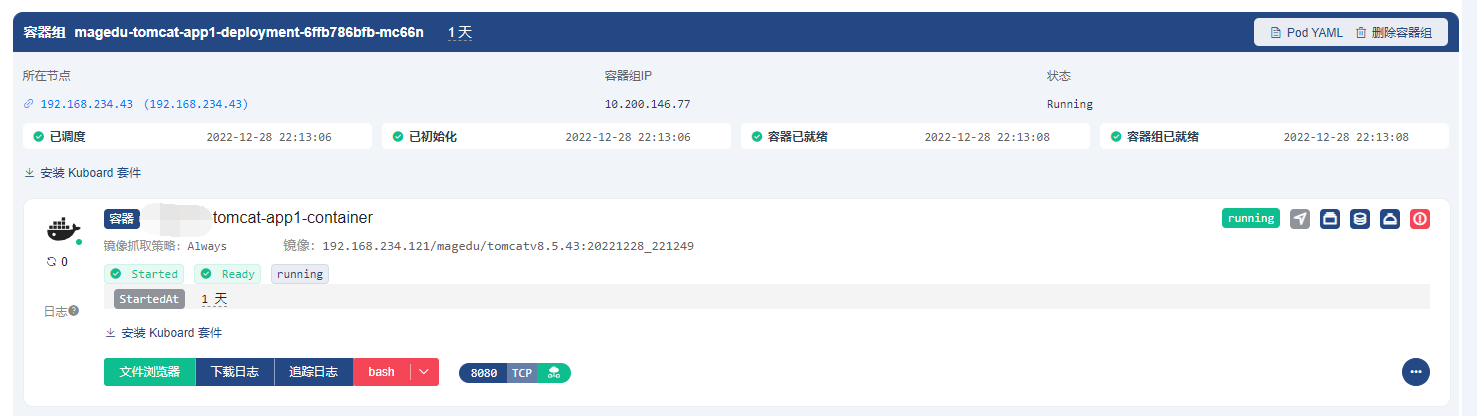
启动pod
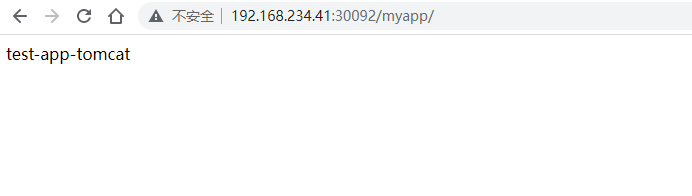
三、验证日志收集
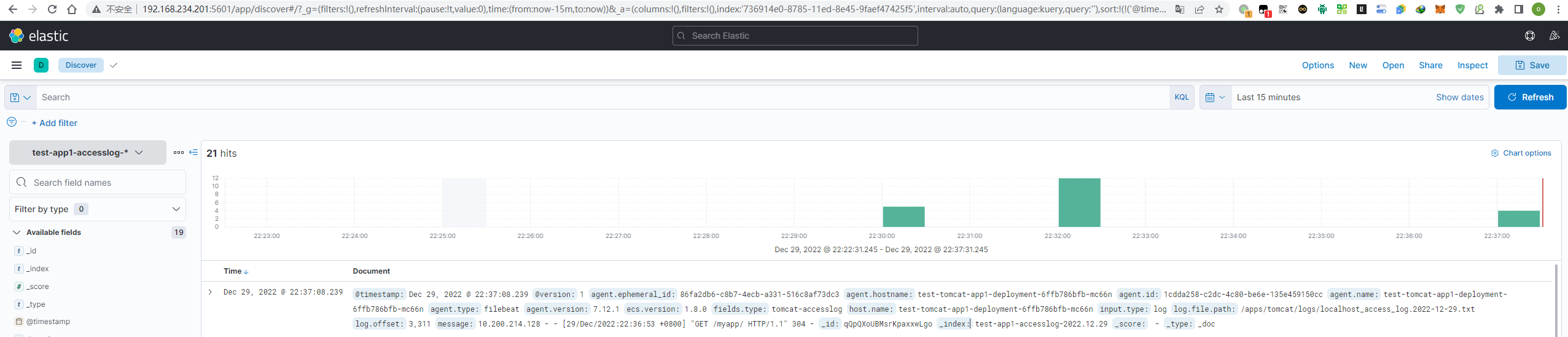
进入192.168.234.201:5601
创建索引
test-app1-accesslog-*
四、总结
1、部署es集群
2、部署zookeeper集群
3、部署kafka集群
4、部署logstash
5、修改filebeat.yaml
6、准备kibana
7、修改好kafka-es的配置文件
8、准备好业务yaml文件